RobustMQ 规则引擎与 AI 结合:技术设计与边界思考
RobustMQ 规划规则引擎,核心驱动力来自 MQTT 场景。设备消息进入 Broker 后常常需要立刻做过滤、字段清洗、格式转换和简单路由;如果全部外置处理,链路和运维复杂度都会快速上升。尤其在边缘场景,外挂重型流计算系统成本过高,因此这项能力是刚需而非可选项。
这也不是 MQTT 独有问题,而是各类 MQ 的共性需求。规则引擎的定位很明确:不替代 Flink 这类系统,不做重型状态计算,只在 Broker 内提供一层轻量、可控的简单任务处理能力。
同时它与 RobustMQ 的内置 AI 能力天然协同:规则引擎负责稳定执行边界,AI 负责降低配置门槛与生成成本,形成“可控执行 + 快速生成”的闭环。
是什么
规则引擎本质上是一层轻量化内置 ETL 能力,不是独立的大型计算系统。它解决的是消息进入 Broker 后的“就地处理”问题:在发送到下游前完成基础过滤、字段清洗、格式转换和路由改写。
如下图所示,从设计上看,它是一个链式处理模型,数据沿着明确顺序依次经过各个算子,最终输出处理结果或被过滤丢弃。
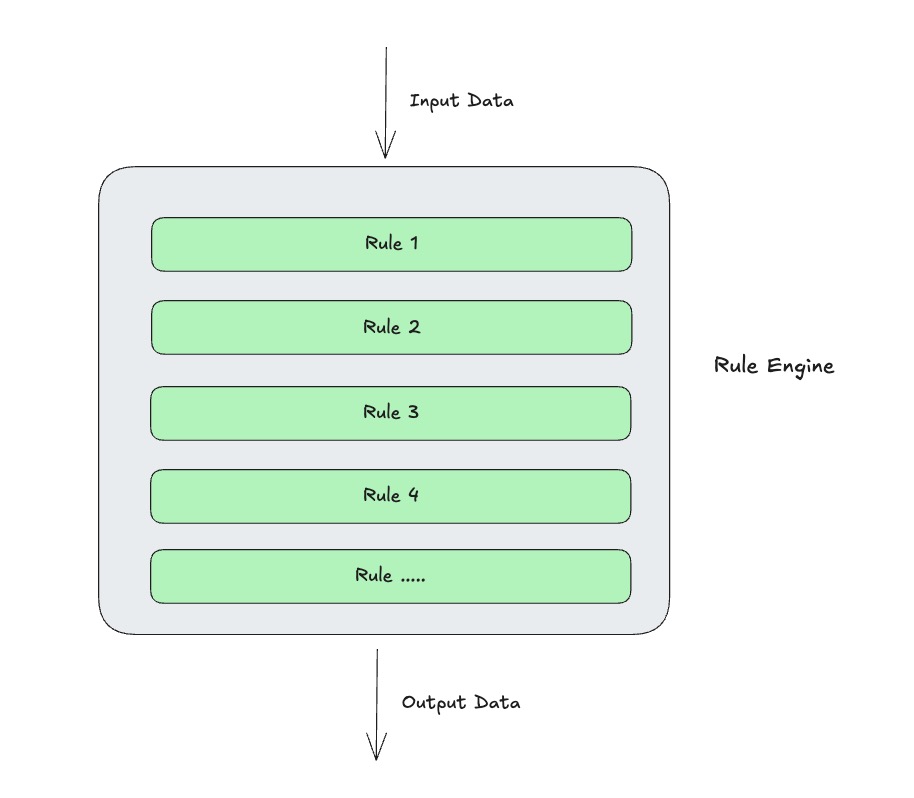
从运行时来看,它是和Connector 配合使用,在Connector 的每条消息处理中执行规则引擎链路,处理数据,然后Connector 将数据写入到下游。
从代码上看,如下所示,它是一段 JSON 配置:ETL Rule链,也就是ops 中的处理链路。每条消息都会应用这个处理规则。从而输出消息。
{
"id": "rule-temp-normalize-v1",
"name": "温度数据清洗",
"enabled": true,
"match": {
"protocols": ["mqtt"],
"topics": ["devices/+/telemetry"]
},
"ops": [
{
"type": "filter",
"expr": "payload.device_id != null && payload.temp != null"
},
{
"type": "set",
"field": "payload.temp_f",
"expr": "double(payload.temp) * 1.8 + 32.0"
},
{
"type": "delete",
"fields": ["payload.raw_bytes"]
}
],
"on_error": {
"strategy": "deadletter",
"topic": "$rule/rule-temp-normalize-v1/deadletter"
}
}这种“轻量 ETL + 强约束模型”的组合,核心价值是降低系统复杂度。很多原本要依赖外部任务编排才能完成的简单处理,能在 Broker 内核直接闭环完成。系统组件更少、链路更短、故障点更少,同时规则治理能力不下降。这就是规则引擎在架构层面的真正意义。
怎么做
从工程实现上,规则引擎按 Runtime、Schema、AI 三层拆分。
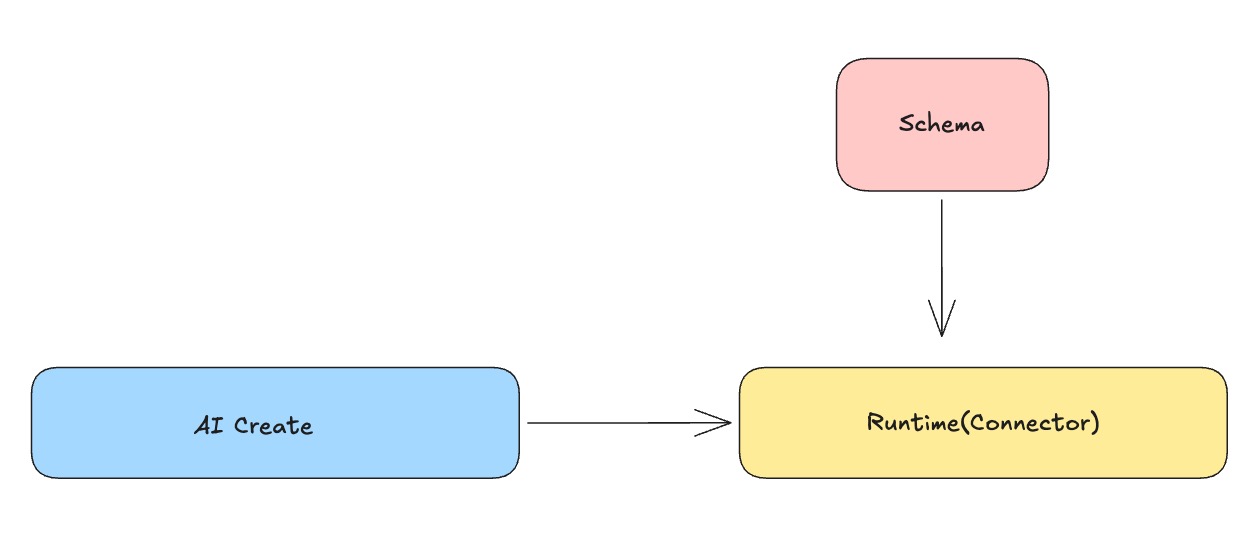
AI 负责把自然语言需求翻译成结构化规则; Runtime 放在 Connector 内执行,负责每条消息的确定性处理;Schema 负责规则结构、字段类型、算子参数等约束。三层拆分的价值在于职责边界清晰:执行路径只关注稳定性,规则定义只关注规范性,交互入口只关注易用性,彼此协作但不相互污染。
在运行路径上,Connector 读取到消息后先进行 match 判定,再按 ops[] 顺序执行算子,最终把处理结果交还给 Connector 写入下游。这里没有独立 sink,因为输出流向由 Connector 上下文决定。这个设计能把规则引擎稳定地嵌入现有数据通路,不额外引入新的路由控制面,避免出现“规则配置”和“Connector 配置”双重路由带来的冲突。
在执行语义上,系统保持无状态、逐条处理,不依赖外部会话上下文。这样做的好处是行为可预测、延迟可控、故障边界清晰,也便于在 MQTT、Kafka 和后续协议场景复用同一套执行内核。对于边缘场景,这一点尤其重要,因为资源受限环境更需要简单、稳定、低开销的执行模型。
在算子实现策略上,动态表达式和结构变换分别处理。filter、set 这类需要表达式能力的算子,使用受约束表达式引擎;rename、delete、decode 这类结构算子,使用固定逻辑实现。这样既保留了必要的表达能力,又避免把全部逻辑脚本化导致的调试复杂、性能抖动和语义漂移问题。最终形成的是一个“规则可扩展、执行可控、治理可落地”的实现框架。
AI 如何结合:生成与执行解耦
AI 与规则引擎结合的核心是“生成与执行解耦”。AI 负责把自然语言需求转换成规则配置,运行时只执行已经通过校验的规则,不在执行路径中引入模型推理。这样可以同时保留 AI 的效率优势和 Broker 场景必须具备的确定性。
这件事的关键落点是 Schema 约束。自然语言输入可以灵活,但最终配置必须满足结构、类型和算子语义约束。也就是说,AI 输出的是候选规则,不是直接执行结果;只有通过 Schema 校验和测试验证后,规则才进入发布流程。
整体流程保持为“生成 -> 校验 -> 测试 -> 生效”。生成失败时返回可修正的错误信息,测试不符合预期时支持继续迭代。AI 负责降低表达门槛,Schema 负责约束合法性,Runtime 负责确定性执行,三者协作后,才能实现“复杂任务自然表达、线上行为严格可控”。
边界是什么:明确不做有状态流计算
规则引擎的边界必须提前定义清楚:它专注无状态、逐条消息处理,解决过滤、字段变换、格式归一化、路由决策这类高频问题。它不承担窗口聚合、多流 Join、复杂 CEP 等有状态流计算能力。这不是能力不足,而是主动的架构取舍。
如果边界不清晰,系统会在短期内获得“看起来更强”的功能集合,但长期会出现语义冲突、资源不可控、性能不可预测的问题。尤其在 Broker 内核中,任何不受控的状态复杂度都会放大运行风险。把高频无状态能力放在内核,把复杂有状态计算交给专门系统,是更稳妥也更可持续的系统分工方式。
从产品视角看,边界清晰还有一个现实意义:它决定系统是否能在边缘和云端同时稳定运行。内核规则引擎必须保持轻量、可部署、可观测,才能真正成为默认能力,而不是只在少数重场景里可用的高级组件。
想做成什么样子:能力形态与目标效果
目标形态不是增加一个规则页面,而是以 RobustMQ 内置 MCP Server 为统一入口,让用户通过自然语言直接生成可执行的数据处理任务。这里强调的不是简单规则,而是多步算子链、条件判断、字段映射和格式转换等复杂任务也能被稳定生成。
整体流程保持“自然语言输入 -> 结构化规则生成 -> Schema 校验 -> 测试验证 -> Runtime 执行”的闭环。对用户来说,入口足够简单;对系统来说,落地仍然是严格结构化配置。这样既能降低复杂任务配置门槛,也能保证线上执行的确定性与可追踪性。
最终希望达到的效果是:复杂任务可以被自然表达,处理链路在 Broker 内完成生成与生效,减少额外系统依赖,同时保持执行严格可控。这也是规则引擎与 AI 结合的长期价值,即可控地规模化交付数据处理能力。