An Edge Case with QoS 2 in Cluster Mode
I've been working on the design for handling QoS 2 in RobustMQ's cluster mode, and I ran into a problem worth thinking through carefully. Here is a record of that thought process.
Where the Problem Comes From
MQTT QoS 2 is a four-step handshake protocol designed to guarantee that a message is delivered exactly once — no more, no less. The flow works like this: the Client sends PUBLISH to the Broker; the Broker receives it and replies with PUBREC to acknowledge receipt; the Client receives PUBREC and sends PUBREL to confirm; finally, the Broker replies with PUBCOMP, completing the handshake, and the message is considered precisely delivered.

In a single-node scenario, this flow is straightforward. The Broker maintains a session state locally, recording which stage of the handshake each Client is currently in, and clears the state after all four steps complete. The logic is simple, the state is complete, and there is no ambiguity.
But in cluster mode, a very natural edge case appears. A Client completes the first two steps, receives PUBREC, and then disconnects for some reason. When it reconnects, the load balancer routes it to a different node. The new node receives PUBREL from the Client, but has absolutely no record of this Client's QoS 2 state locally — it has no idea where this message came from or how to handle it.
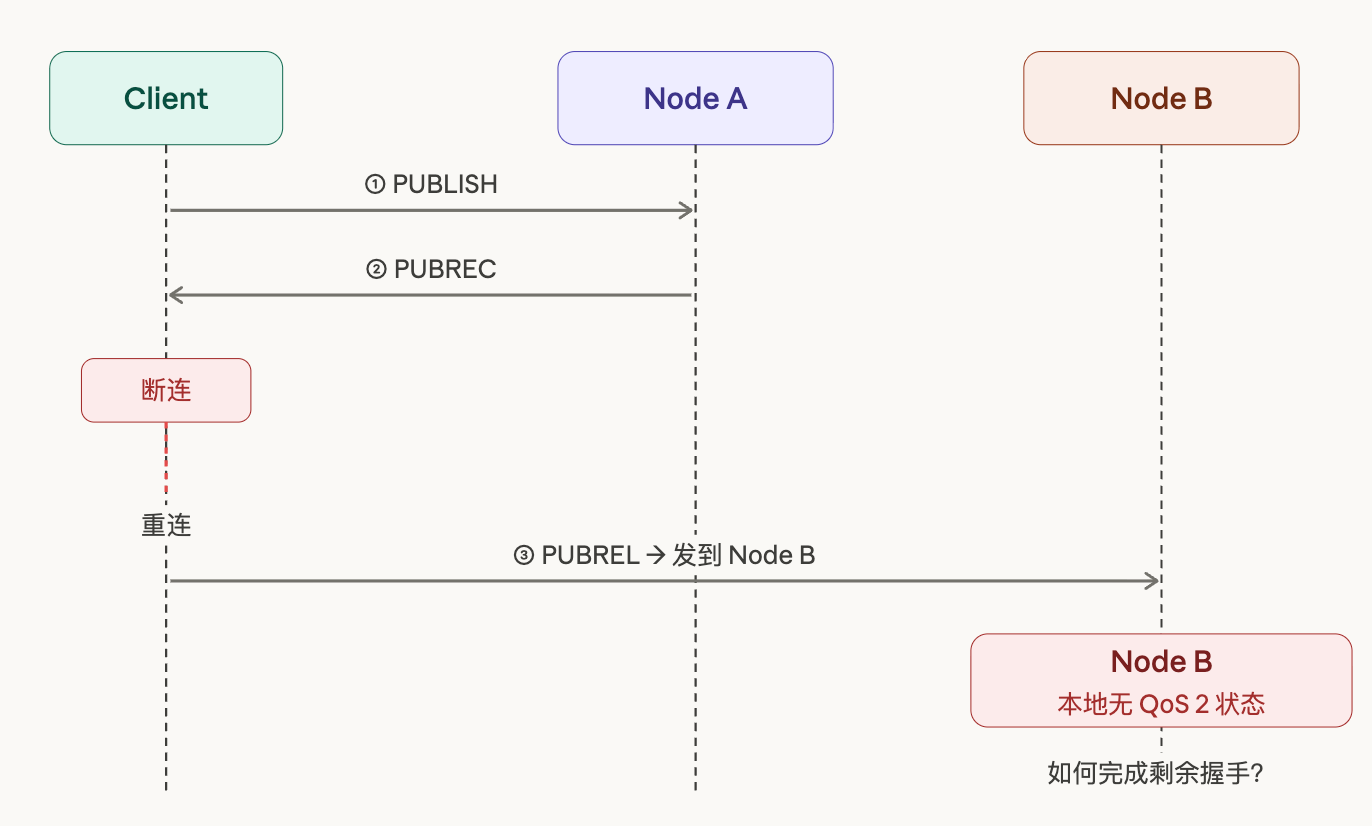
This is not an extreme hypothetical, nor a test scenario that needs to be deliberately constructed. Network jitter, load balancer switchover, node restarts — any of these can trigger this problem. In moderately large IoT deployments, events like these happen every day.
Why Existing Solutions Fall Short
There are two relatively mature approaches in the industry for handling this problem, but each has its own cost.
The first is maintaining a global routing table that records which node each ClientId is currently connected to. When any node receives a request, it first queries this table, finds the node holding the session, and forwards the request there. This approach has clear logic, correctness is easy to guarantee, and it works well in small clusters.
But the problem lies in the word "global." This routing table needs to be synchronized in real time to all nodes in the cluster — if the cluster has 1 million connections, that's 1 million records. Every time a Client connects or disconnects, a cluster-wide broadcast must be triggered to sync the change to every node. The more cluster nodes there are, the higher the sync overhead, and the greater the risk of a network storm. The constraint behind the cap on cluster node count is partly the synchronization pressure of the global routing table.
The second approach is more aggressive: write QoS 2 session state directly into Raft, so all nodes can query it, cross-node handling has no obstacle, consistency is guaranteed by Raft, and the problem disappears at the root. This sounds clean, but the cost is that every handshake step requires a Raft write. QoS 2 itself is four steps; in high-concurrency scenarios, this cost is non-trivial, and Raft write latency will be directly reflected in message throughput.
Both of these approaches are essentially using a full-scale, continuously-running piece of infrastructure to solve a low-probability problem that only occurs under abnormal conditions. The machinery for solving the problem is heavier than the problem itself — this is not a great trade-off.
First, Think Through the Probability Distribution of the Problem
Before designing any solution, there is one thing that should be done first: think clearly about how often this problem actually occurs.
In a normally operating production environment, the vast majority of Client connections are stable. PUBLISH is sent, the four-step handshake completes on the same node, PUBCOMP goes back — this is the high-probability path, the one the system takes 99% of the time. The cross-node case only occurs during network jitter or node switching; it is the low-probability path, and its very prerequisite is an abnormal event.
If you design a full-scale synchronization scheme for this low-probability path, you end up paying the cost of cross-node synchronization on every normal handshake, just to handle a rare few. The performance of the high-probability path is dragged down by the design for the low-probability path — this is putting the cart before the horse.
A more reasonable approach is to flip this around: make the high-probability path zero-overhead, handle the low-probability path on demand, and let overall performance be determined by the actual proportion of cross-node requests rather than the total connection count. The difference between these two can be an order of magnitude in large-scale scenarios.
Our Solution: Local-First with On-Demand Broadcast Discovery
Based on this judgment, RobustMQ chose a strategy of local-first plus on-demand broadcast discovery.
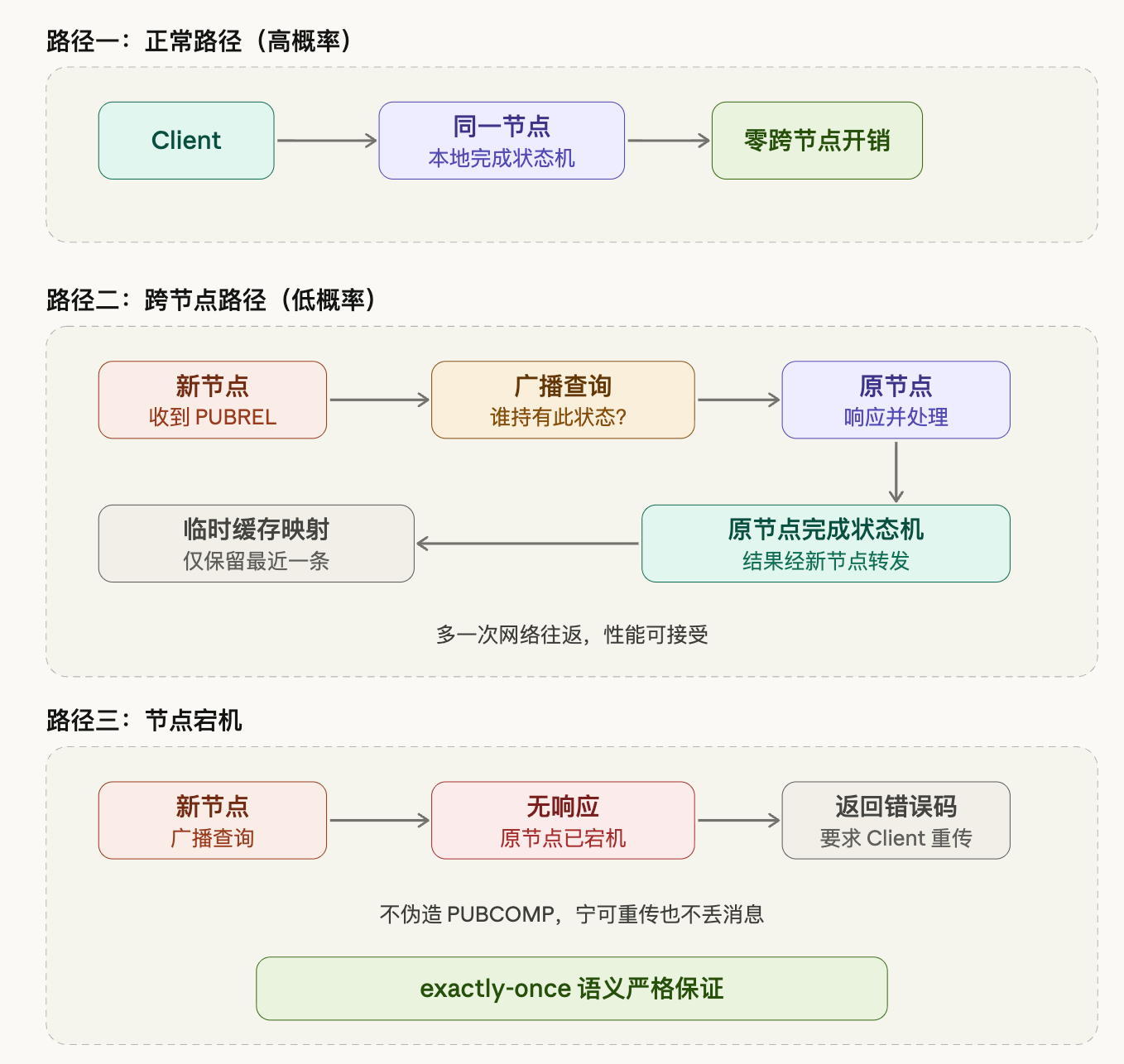
On the normal path, the Client stays on the same node throughout, QoS 2 state flows through locally, and there is no cross-node interaction whatsoever. This is also the path taken by the vast majority of requests; the overhead on this path is no different from a single-node setup.
When the cross-node case does occur, the handling logic works as follows: the new node receives PUBREL, can't find the corresponding state record locally, and broadcasts a query to the cluster: who holds the QoS 2 state for this Client? The node holding the state responds, the new node temporarily caches this mapping, then forwards the request to the original node. The original node completes the remaining state machine transitions and sends the result back through the new node to the Client.
The temporary cache only retains the most recent entry. If a Client frequently disconnects and reconnects, the hit value of historical mappings is actually very low — each reconnect may land on a different node, and retaining too much history is wasteful. The worst case is having to go through the broadcast every time, adding one extra network round trip, which is an acceptable cost and does not affect correctness.
Node failure is a case that needs separate handling. The broadcast goes out, but no node responds — this means the node holding the state has already failed, and that QoS 2 intermediate state was lost along with the node. In this situation, the handling is: return an error code, ask the Client to retransmit PUBLISH, and go through the handshake from the beginning.
There is one principle that cannot be compromised: do not forge PUBCOMP. The semantic promise of QoS 2 is exactly-once delivery. If we pretend the handshake is complete when state has been lost, the message is truly gone and the Client has no idea. Better to have the Client send one more time — a retransmission is just the cost of one more handshake; the message won't be lost. The correctness of the protocol semantics is more important than avoiding one retransmission.
Handling Pressure During Large-Scale Disconnect/Reconnect Events
The solution is clear overall, but there is one more edge case that deserves careful attention: a large number of Clients disconnecting and reconnecting simultaneously.
This is not uncommon in practice — a network partition recovery, or a planned rolling restart of nodes, can both produce tens of thousands of Clients reconnecting within a short time window. All of these Clients' PUBRELs land on new nodes, none of which find the state locally, generating a large burst of broadcast requests in a very short period — a noticeable traffic spike.
Rate limiting is one approach, but there is a more elegant way to handle it: batch merging. Set a 30-millisecond aggregation window on the new node side: all cross-node PUBREL requests that accumulate within the window are not broadcast immediately but instead merged into a single batch node call at the end of the window, sent to the target node, which then batch-queries and batch-returns:
Within a 30ms window:
ClientA / pkid=1
ClientB / pkid=5
ClientC / pkid=8
↓
Merged into a single request sent to the target node
Target node batch-queries and batch-returnsThis way, the total number of node calls is determined by the window size, not the number of cross-node requests. Even if 100,000 Clients disconnect and reconnect simultaneously, within the 30-millisecond window the number of node calls remains controllable and independent of cluster node count. The batch window itself is a natural peak-shaving mechanism — no additional rate-limiting logic is needed. A 30-millisecond delay is completely acceptable for MQTT session recovery, but it buys protection against broadcast storms.
For the case of a single Client repeatedly disconnecting and reconnecting, the temporary cache only retains the most recent mapping, reducing the risk of accumulation. The worst case is frequently going through broadcasts, which incurs some performance cost, but does not affect correctness.
Why This Solution
Behind this solution is a fundamental judgment: don't optimize every path individually — optimize the overall expected value.
Concentrate resources on the high-probability path, make it extremely lightweight — this is the state of the system the vast majority of the time, and its performance should be good. Accept reasonable performance degradation on the low-probability path: one extra broadcast, one extra network round trip, but without sacrificing semantic correctness and without letting the cost of handling the low-probability path bleed into the normal path. For extreme cases like node failure, there is a clear handling strategy: no gray areas, no dishonest fallback.
This is not a complicated solution, but the prerequisite is having thought through the problem itself clearly. Much of the "heaviness" in system design comes from not carefully analyzing the probability distribution — treating a low-probability problem as a normal case requiring full-scale defense. Once you think through the frequency of a problem, the right solution is actually not that hard to find.