FlowMQ Technical Architecture Analysis and Speculation
All analysis in this article is technical reasoning and personal thinking based on FlowMQ's public documentation. It does not represent FlowMQ's actual implementation, makes no guarantee of accuracy, and does not constitute any disparagement of EMQ or FlowMQ. It is intended solely for technical exchange and learning, and corrections are welcome.
Background
On March 20, 2026, EMQ officially launched FlowMQ at Tech Day, positioning it as a "next-generation converged message streaming platform." FlowMQ provides three messaging capabilities within a single system — Subscription (real-time push), Stream (data streaming), and Queue — with native support for MQTT, Kafka, and AMQP multi-protocol ingestion and cross-protocol interoperability.
Regarding FlowMQ's technical origins, the following public clues are available:
- The HStreamDB website hstream.io now 301-redirects to flowmq.io
- The flowmq-io organization on GitHub has forked FoundationDB (C++), Bento (Go), and Paho MQTT Testing, among other projects
- EMQ founder Feng Lee's GitHub contains an early repository named flowmq, described as "An experimental MQTT broker written in C++"
- The FlowSDK on EMQ's GitHub is described as "A safety-first, behavior-predictable MQTT 5.0 SDK written in Rust"
EMQ has not officially confirmed the relationship between FlowMQ and HStreamDB, nor has it disclosed the implementation language of the FlowMQ Broker. FlowMQ may have inherited some architectural concepts from HStreamDB, or it may be an entirely new implementation — the specific details cannot be confirmed from the outside.
All analysis below is based on FlowMQ's public documentation and logical reasoning.
I. Product Positioning Evolution
HStreamDB was open-sourced in 2021, written in Haskell, and positioned as a "streaming database" focused on storing and real-time processing of streaming data, with SQL as its primary interface. The project stalled at v0.14, with relatively low community activity.
FlowMQ's positioning has undergone a fundamental shift: from "streaming database" to "unified messaging platform." The core narrative has changed to replacing an enterprise's scattered MQTT Brokers, Kafka clusters, and RabbitMQ instances with a single system, eliminating bridging programs and duplicate operations overhead.
At the same time, EMQX has merged its community and enterprise editions starting from v5.9.0, changing the license from Apache 2.0 to BSL 1.1, and the EMQX 5.8 open-source version reached end-of-maintenance in late February 2026. EMQ's entire product line is no longer open source in the traditional sense.
II. Overall Architecture Speculation
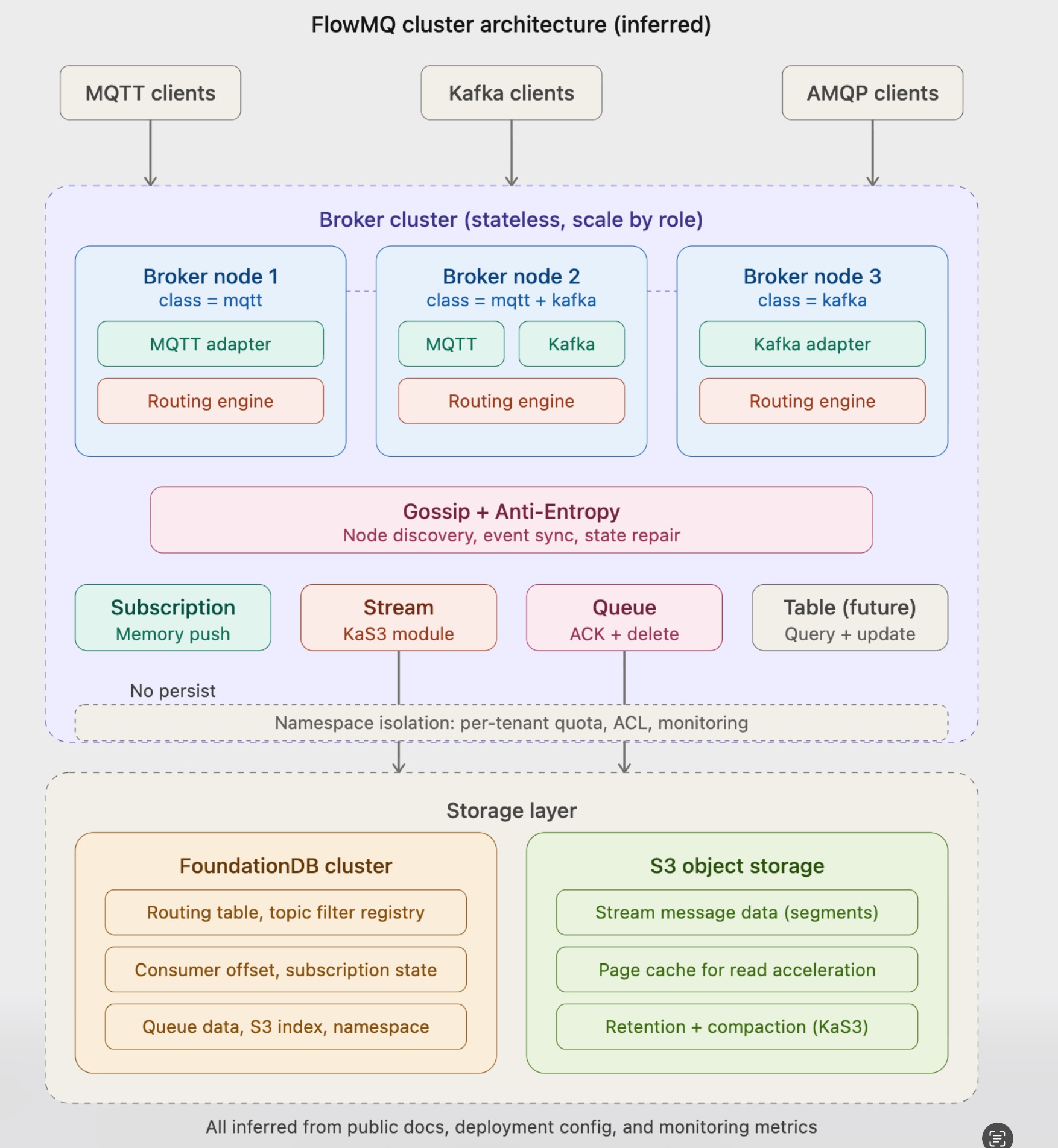
Based on public documentation, FlowMQ's architecture can be divided into four layers: the protocol adaptation layer, routing engine, Destination layer, and storage layer. The following are speculative overall architecture and routing engine internal logic diagrams based on public information.
Overall Architecture Diagram (Speculative)
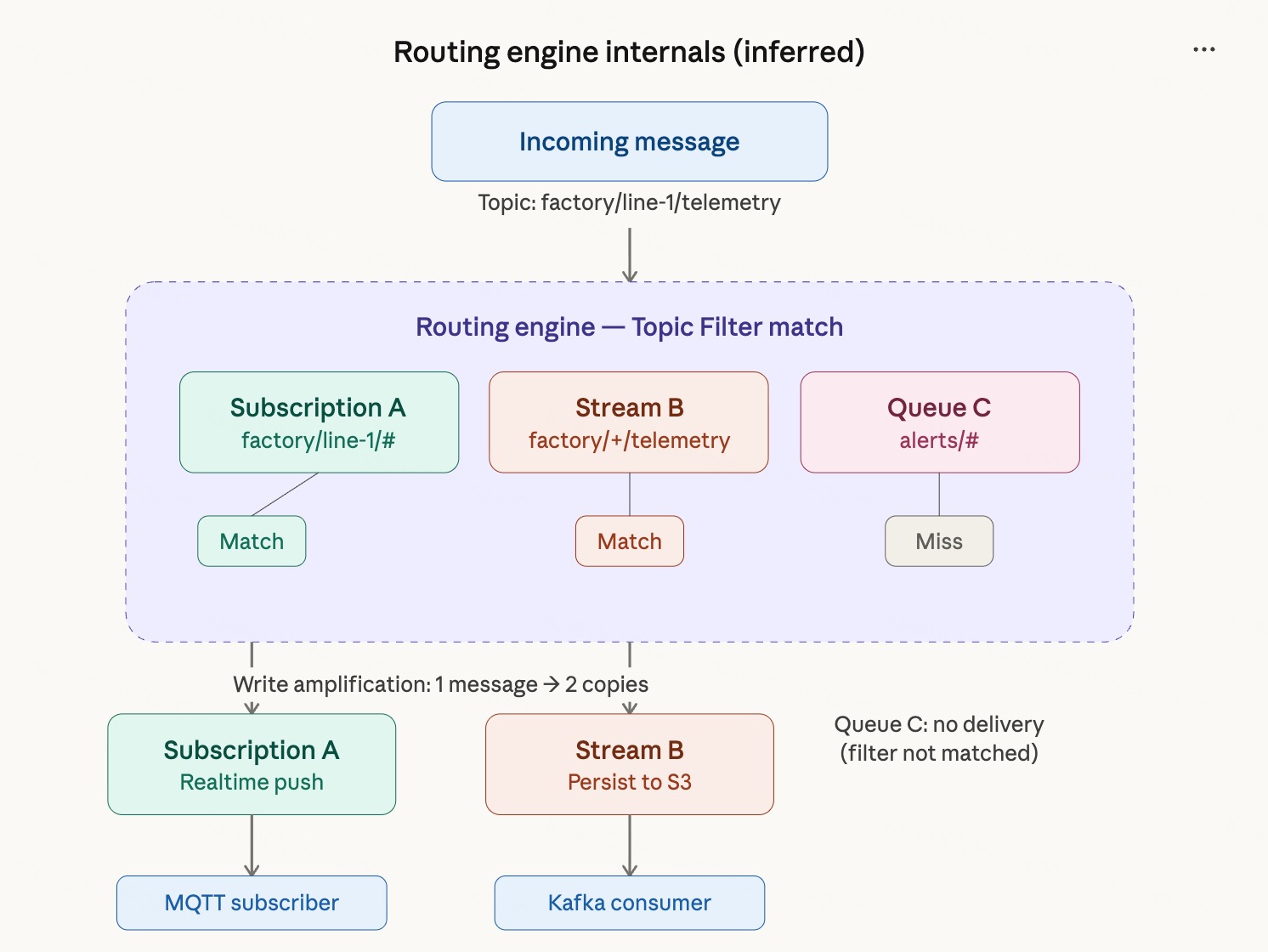
Routing Engine Internal Logic (Speculative)
2.1 Protocol Adaptation Layer
Each protocol has its own independent adapter, responsible for translating external protocol messages into an internal unified format and mapping protocol-specific addresses to FlowMQ internal Topics:
- MQTT topics are mapped directly
- Kafka topic
.characters are automatically converted to/ - AMQP message keys are mapped to Topics
Adapters are pluggable — adding a new protocol only requires adding a new adapter. Deployment configuration supports independent scaling by protocol role, with mqtt-num and kafka-num controlling instance counts separately, allowing mixed deployment of different roles on the same machine.
2.2 Routing Engine
The routing engine is the core hub of the architecture, responsible for matching a message's Topic against all Topic Filters registered by Destinations (supporting + and # wildcards) and delivering on a match.
The routing engine is completely protocol-agnostic and does not distinguish by the message's source protocol. Cross-protocol interoperability happens naturally at this layer.
If a single message matches multiple Destinations (for example, simultaneously matching a Subscription and a Stream), the message is copied and delivered to each of them, producing write amplification.
2.3 Destination Layer
Three Destination types correspond to three message semantics:
Subscription: Upon arrival, messages are immediately pushed to online subscribers without going through persistence. Based on monitoring metrics, Subscriptions use in-memory direct push, with the lowest latency.
Stream: Messages are persisted to S3 object storage in append-only log format, supporting partitions, offset-based consumption, and historical replay, with full Kafka protocol compatibility. Streams support binding to a Topic Filter to automatically capture matching messages. Based on the kas3_ prefix in monitoring metrics, there appears to be a KaS3 module underneath specifically managing page cache, segments, compaction, and retention.
Queue: Competing consumers, deleted after ACK confirmation. The documentation does not clearly specify Queue data storage details; it is speculated to be stored in FoundationDB.
The documentation mentions that the Destination design supports extensibility, with new types such as Table planned for the future.
2.4 Cluster Management
Confirmed from monitoring metrics, FlowMQ uses the Gossip protocol for node discovery and event broadcasting, and Anti-Entropy for periodic state synchronization and repair:
gossip_cluster_size: cluster node countgossip_events_originated_count: events originating from this nodegossip_event_propagation_hops_count: event propagation hop countanti_entropy_syncs_completed_count: successful sync countanti_entropy_missing_events_detected_count: detected missing event count
Broker nodes are stateless and can scale in or out in seconds, or be replaced quickly after failure, without rebalancing.
2.5 Metadata Interaction
The speculated interaction pattern between Brokers and FoundationDB is:
- On startup, pull all metadata (routing tables, Destination configurations, Namespaces, etc.) from FoundationDB and load into local memory
- Route matching is done entirely in memory — FoundationDB is not queried per message
- At runtime, metadata changes are written to FoundationDB as the source of truth and broadcast to all nodes via Gossip to update in-memory caches
- Anti-Entropy periodically does a full reconciliation to repair changes missed by Gossip
- High-frequency updates such as consumer offsets are checkpointed in memory and periodically batch-flushed to FoundationDB
2.6 Storage Layer
FoundationDB: The deployment configuration directly uses native tools such as fdbserver, fdb.cluster, and fdbcli, with the package named flowmq-meta. It handles metadata storage for routing tables, Destination configurations, subscription relationships, Consumer Offsets, and Namespace isolation. It is also speculated to store Queue data and S3 index data.
S3 Object Storage: In the deployment configuration, S3 parameters only need to be configured when Kafka functionality is enabled, indicating that Stream data is stored in S3 while Subscription data does not pass through S3. Supports AWS S3, Alibaba Cloud OSS, Ceph, MinIO, and others.
III. Cross-Protocol Interoperability Mechanism
Using MQTT → Kafka as an example:
- An IoT device publishes a message via MQTT to
sensors/device-001/telemetry - The MQTT adapter maps it directly to a FlowMQ Topic
- The routing engine matches it against a Stream bound to Topic Filter
sensors/+/telemetry - The message is written to the Stream and persisted to S3
- A Kafka consumer consumes from this Stream by offset; the topic name is automatically mapped to
sensors.device-001.telemetry
Reverse Kafka → MQTT:
- A backend service writes to
commands.broadcastvia a Kafka producer - The adapter converts
.to/, mapping to Topiccommands/broadcast - The routing engine matches it against a Subscription's Topic Filter
commands/# - The message is pushed directly in-memory to online MQTT subscribers without being written to disk
The core mechanism is the routing engine performing distribution — not different protocols reading from and writing to the same data. If a single message matches both a Subscription and a Stream, it is processed twice.
IV. Technical Choice Analysis
The Choice of FoundationDB
Strong consistency transactions are a natural fit for metadata management; there is no need to implement Raft/Paxos from scratch, and it has been validated at scale by Apple in production. The trade-off is introducing a distributed cluster that requires independent operations.
The Choice of S3 Object Storage
Storage costs are far lower than block storage, capacity scales on demand, and durability is guaranteed by cloud providers. Stateless Brokers can scale in or out in seconds. This is consistent with the approaches of AutoMQ and WarpStream.
Implementation Language
Cannot be confirmed. Known clues: the founder's GitHub has an early C++ experimental repository; HStreamDB is in Haskell; FlowSDK is in Rust; FoundationDB is in C++. The production code has not been made public, so it would be inappropriate to draw conclusions from early-stage information.
V. Architecture Pros and Cons
Pros
- Clean decoupling between protocol, routing, and storage layers; good extensibility
- Stateless Brokers + object storage enable strong elastic scaling
- MQTT and Kafka instances can be independently scaled by role
- Cross-protocol interoperability works out of the box, no bridging needed
- Gossip + Anti-Entropy cluster management does not depend on additional coordination services
Cons
- A message matching multiple Destinations produces write amplification
- Deployment requires at least three components: a FoundationDB cluster + S3 + FlowMQ Broker
- Strong dependency on FoundationDB and S3 expands the failure domain
- Automatic conversion between Kafka's
.and MQTT's/is a hard-coded rule with a risk of mapping collisions - Closed-source commercial product carries vendor lock-in risk
VI. Further Thinking
The following are personal technical opinions and speculation, and do not represent any disparagement of FlowMQ or EMQ. There is no absolute right or wrong in architectural trade-offs — different designs serve different constraints and goals. Technical discussion is welcome. These views are based on my speculated architecture. If the premises of the speculation are wrong, the views below may also be wrong.
6.1 External Dependencies and Failure Domain
A messaging system is the infrastructure of infrastructure — the shorter its own dependency chain and the more controllable it is, the better. FlowMQ's strong dependency on FoundationDB + S3 expands the failure domain from itself to two external systems. The history of Kafka removing ZooKeeper and Pulsar's struggles with BookKeeper have repeatedly demonstrated: external dependencies in a messaging system are real architectural risks, not merely operational cost issues.
6.2 Routing Engine and Storage Unification
The existence of the routing engine implies that Subscription, Stream, and Queue do not share the same underlying storage — otherwise, a routing layer for copy-and-dispatch would not be needed. If the underlying storage were a unified model, a message would only need to be written once, and different consumers would use different read perspectives to consume the same data, with no intermediate dispatch logic needed.
The ultimate goal of multi-protocol unification should be "one copy of data, multiple consumption perspectives," not "one message, routed and copied into multiple copies by the routing engine, then consumed separately."
6.3 Pre-planning Requirements and Write Amplification
FlowMQ requires users to plan Destinations in advance and bind Topic Filters. Adding a new Destination when requirements change means writing one more copy, and write amplification grows with the number of Destinations. In a unified storage architecture, changes in consumption requirements should not affect the write path, and users should not need to plan consumption paths in advance.
6.4 The Ceiling of a Compositional Architecture
FlowMQ delegates its core storage to FoundationDB and S3, while controlling protocol adaptation and routing distribution itself. As the product evolves (Queue needs ACK deletion and retry, future Table needs query and update), FoundationDB will very likely gradually take on more business data beyond pure metadata storage — its role will grow heavier, and the system's dependency on FoundationDB and the performance pressure on it will increase.
The storage layer is the core competitive differentiator of a messaging system. Using an external general-purpose distributed KV for storage is simpler from an engineering perspective, but in the long run it limits the room for extreme optimizations tailored to messaging workloads. The various components in the foundational software space are already mature enough. A next-generation messaging engine should solve more fundamental problems — a unified storage model — rather than assembling existing components one more time.
VII. Summary
FlowMQ's architecture makes sense from an engineering delivery perspective. EMQ has ten years of MQTT experience and a mature enterprise customer base, and this architecture can ship a product quickly, get it running, and generate revenue. Choosing this path is their current-stage optimal solution.
But from a personal technical philosophy standpoint, I have a few differing views:
On the overall architecture: clear layering and thorough decoupling are genuine strengths. But it doesn't quite align with my pursuit of high cohesion. S3 as one storage option is reasonable, but it should not become the primary storage engine. A messaging system's storage layer should be controlled by the system itself; object storage can serve as a supplement for cold data archival or long-term retention, not as the foundation of the core data path.
On the choice of FoundationDB: it's hard to say whether it's right or wrong. FoundationDB itself is an excellent distributed KV store, and using it for metadata management saves a huge amount of engineering work. But personally I prefer not to introduce a new external distributed component into a messaging system — the core storage layer should be self-controlled, so that there is room for extreme optimization and full controllability.
On the Destination design: this is the part I am least convinced by. The routing engine distributes copies of messages to multiple Destinations, which is fundamentally multiple copies of the same data. I believe the more sensible direction is one copy of data with multiple consumption views — data is written only once, and consumers of different protocols consume the same data using different read semantics. Changes in consumption requirements should not affect the write path, nor should they produce additional storage costs. (This point may also reflect a misunderstanding on my part — if it is already one copy, this problem does not exist.)
On the long-term risk of FoundationDB: whether FoundationDB will become a historical burden like Kafka's ZooKeeper or Pulsar's ZooKeeper and BookKeeper remains to be seen. But the historical track record of the messaging system space has repeatedly demonstrated that heavy external dependencies are an architectural risk that requires long-term vigilance.
All of the above are personal technical opinions and do not represent a rejection of FlowMQ or EMQ. Different design choices serve different constraints and goals, and FlowMQ's architecture makes complete sense in EMQ's commercial context. There is no absolute right or wrong in technical paths — ultimately it is the market and users who judge. Discussion is welcome.
- FlowMQ Product Overview
- FlowMQ Core Features
- FlowMQ Core Concepts
- FlowMQ Message Routing
- FlowMQ Cross-Protocol Interoperability
- FlowMQ Data Streaming
- FlowMQ Cluster Deployment
- FlowMQ Metrics Monitoring
- FlowMQ Official Website
- FlowMQ Launch Blog
- EMQX BSL License Announcement
- HStreamDB GitHub
- flowmq-io GitHub
- EMQ Founder GitHub
Disclaimer
All architectural analysis and technical speculation in this article is based on logical reasoning derived from FlowMQ's public documentation, official website information, and public GitHub repositories. It does not represent EMQ's official technical implementation details and does not guarantee full consistency with FlowMQ's actual architecture. FlowMQ is a closed-source commercial product; its internal implementation details cannot be fully confirmed from the outside. This article is intended solely for technical exchange and learning, and does not constitute any disparagement of any product or team. Corrections are welcome if anything is inaccurate.