RPC over Message Queue 可能是最适合 Agent 的通信方式
从 NATS request-reply 说起
NATS 从一开始就支持 request-reply。一行代码就能跑:客户端发个请求到 subject,server 端订阅那个 subject 处理完写回响应。从工程角度看这是个很优雅的设计,complete 的双向通信能力,自动管理 inbox、correlation、超时,比自己用 publish/subscribe 拼一遍 RPC 简洁得多。
但实际工程里,NATS 的 request-reply 几乎没人用。
要做服务间通信,工程师会选 HTTP、选 gRPC、选 REST,不会选 NATS request-reply。原因不复杂:传统服务通信场景下,HTTP/gRPC 已经是事实标准。生态成熟、工具齐全、运维成熟、所有工程师都熟。用 NATS request-reply 做 RPC 意味着引入一个消息中间件、让所有 client 和 server 都连上这个 broker、然后用一种工程师不熟悉的模式做本可以用 HTTP 直接做的事。这是典型的 over-engineering。
NATS 的官方文档自己也承认这一点。在 NATS 的使用场景列表里,request-reply 通常排在 pub/sub、streaming、JetStream 之后,是个"也支持但不是主推"的能力。社区案例里用 NATS 做 IoT 消息、做服务编排、做数据管道的居多,做 service-to-service RPC 的稀少。这不是 NATS 设计得不好,是 request-reply over message queue 这个模式在传统场景下没有存在的必要。
但 Agent 时代不一样。同样的模式,在 Agent 通信场景下从 over-engineering 变成了刚需。
HTTP RPC 在 Agent 场景下不够用
要看清楚这个判断,先回到 RPC 本质。RPC 就是"请求-响应"模式,让一个进程能调用另一个进程的能力。同步阻塞、看起来像本地函数调用、底下通信细节屏蔽。HTTP、gRPC、JSON-RPC 都是这个模式的实现。
同步阻塞 RPC 对接收方有强假设:接收方必须在线、必须快速响应、调用方必须等待。这三个假设在传统微服务场景下基本成立。服务一直在线、响应在毫秒级、调用方等几百毫秒可以接受。所以 HTTP/gRPC 这种"同步 RPC over 长连接"成为主流。NATS request-reply 在这种场景下没机会,因为 HTTP 已经满足需求。
但在 Agent 场景下,这三个假设全都不成立。
Agent 经常离线。LLM Agent 按需启动、Edge Agent 网络断断续续、跨 region 部署的 Agent 可能在维护、本地 Agent 可能机器关了。同步 HTTP 调用一个离线 Agent 直接失败,你得在应用层自己实现 retry、backoff、circuit breaker,每次失败都是个工程坑。
Agent 响应可能很慢。LLM 推理几秒到几分钟很正常,多步工具调用更慢,等待人工审批可能几小时。同步 HTTP 要么超时(默认 30 秒、120 秒,远远不够),要么连接一直挂着浪费 socket。这种长任务场景同步 RPC 天然不匹配。
调用方等不起。一个 LLM agent 经常并行调用多个其他 agent 协作完成任务,找翻译、查数据、做计算、生成图片。要是每个调用都同步阻塞,整个 agent 就被最慢的那一个拖死。Agent 架构里异步是默认形态,不是优化项。
Message Queue 的能力正好对上 Agent 的需求
当 HTTP RPC 的三个核心假设都失效时,必须找新的实现方式。这时候 message queue 作为底层就变得合理。消息持久化天然支持接收方离线、消息可以在队列里等多久都行天然支持慢响应、调用方发完消息就走天然支持并行调用。message queue 的核心能力正好覆盖 HTTP RPC 在 Agent 场景下的弱点。
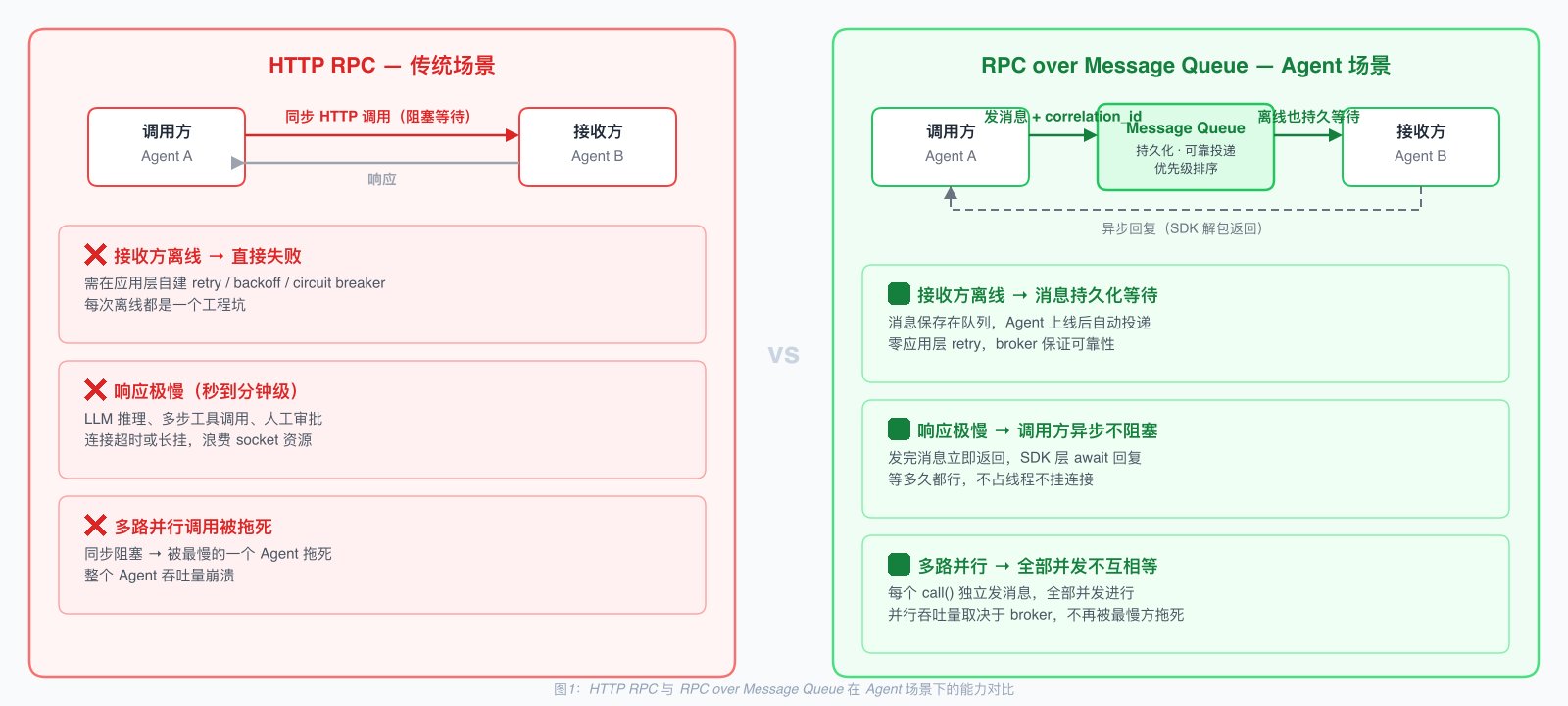
但纯 message queue 模式让应用层直接处理消息收发、订阅、correlation 管理太复杂。开发者想要的接口是 result = await call(agent_id, params),不是 publish + subscribe + match correlation_id 这一堆步骤。这是 message queue 在传统场景下吃力不讨好的真实原因:能力对,但接口对开发者不够友好。
RPC 接口 + Message Queue 底层
解法其实很自然:底层用 message queue 解决工程现实问题(异步、可靠、持久化、负载均衡),上层用 RPC 接口屏蔽复杂性给开发者。这就是 RPC over Message Queue。
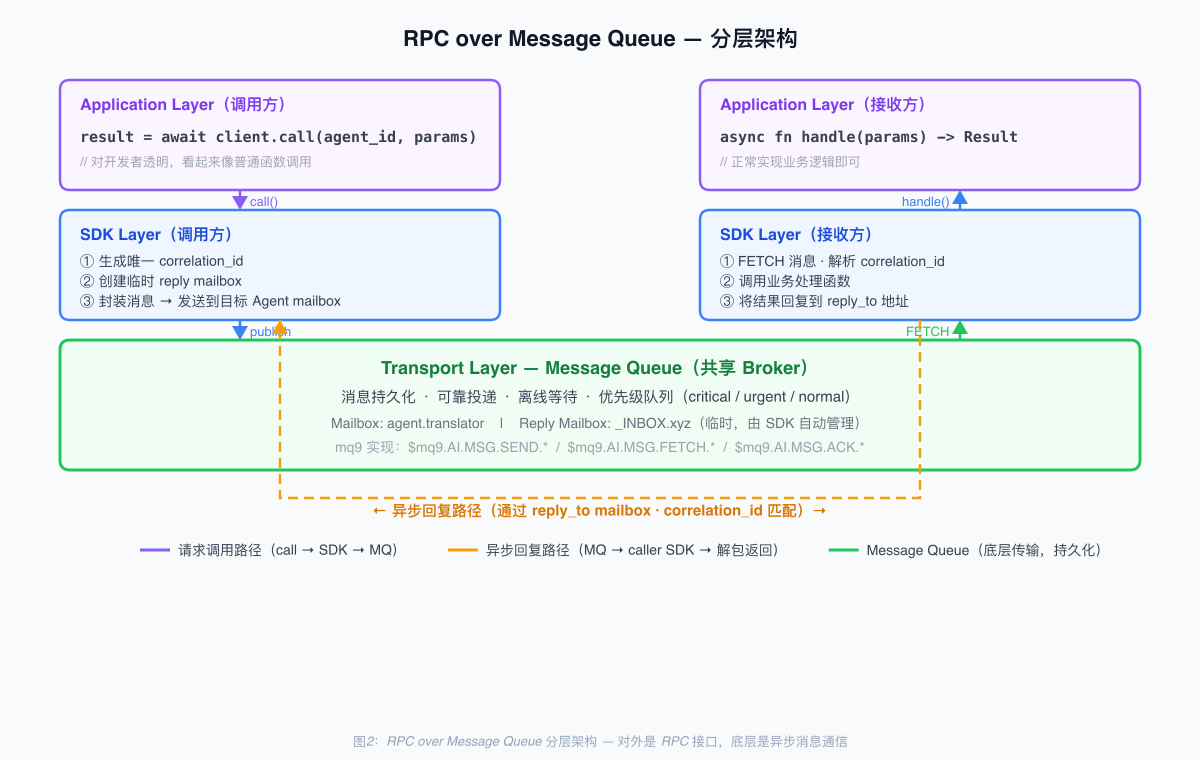
具体怎么实现?发送方调用 result = await client.call(agent_id, params) 时,SDK 在底下做这些事:生成一个唯一的 correlation_id、创建一个临时回复 mailbox、把 params 包装成消息带上 correlation_id 和回复地址发到目标 agent 的 mailbox、在 SDK 层 await 这个回复 mailbox 的第一条消息、收到回复后解包返回。调用方看到的接口是同步的 await,底下的通信是异步的消息流转。API 层是 RPC,传输层是 message queue。
这个模式不新。NATS request-reply 早就这么实现的,AMQP/RabbitMQ 的 RPC pattern、ZeroMQ 的 REQ/REP 都是这个思路。但在传统场景下大家不用,因为 HTTP 直接调用更简单。Agent 场景下大家会用,因为 HTTP 直接调用根本不可行。同样的技术,因为应用场景的根本变化,从无人问津变成了刚需。
回顾历史
这种变化以前也发生过。
容器化早期被认为是 over-engineering,虚拟机一个应用一个 VM 不就行了么,搞容器干嘛。但当应用规模、迭代速度、资源利用率的要求变化后,容器化从 over-engineering 变成事实标准,Kubernetes 成为云原生时代的核心基础设施。
Service Mesh 也是类似。传统服务通信用 HTTP 直连就行,搞个 sidecar 多此一举。但当服务数量上千、跨语言、需要统一治理时,service mesh 从 over-engineering 变成必需。
RPC over Message Queue 在 Agent 时代走的是同样的路径。传统场景下没必要,新场景下成为刚需。
技术本身没变,但场景变了之后,过去的 over-engineering 变成了今天的事实标准。NATS request-reply 在传统场景下没人用,不是因为它设计得不好,是因为它解决的问题在那个场景下不存在。HTTP 已经够了,引入消息中间件做 RPC 是 over-engineering。但 Agent 时代把场景翻转了。HTTP 的核心假设全部失效,message queue 的核心能力全部刚需。同样一种技术形态,场景变了价值就完全不同。
RPC over Message Queue 的故事在 Agent 时代刚刚开始。3-5 年后回头看,Agent 时代的服务通信范式应该不再是 HTTP/gRPC,而是 RPC over Message Queue。这个判断要不要成立,时间会回答。