Meta Service Architecture
Technology Stack
gRPC + Multi Raft (openraft) + RocksDB
- All communication, both between nodes and with external clients, uses gRPC
- Multi Raft is implemented using openraft, providing multi-node data consistency
- RocksDB persists all data, including Raft logs and snapshots
Responsibilities
| Responsibility | Description |
|---|---|
| Cluster coordination | Node discovery, join/leave management, inter-node data distribution |
| Metadata storage | Broker node info, Topic configuration, Schema, Connector configuration, Storage Engine shard metadata |
| KV business data | MQTT Session, retained messages, will messages, subscriptions, ACL, blocklist, and other runtime data |
| Consumer offsets | Consumer group offset commit and management |
| Controller | Session expiry cleanup, Last Will delayed delivery, Storage Engine GC, Connector task scheduling |
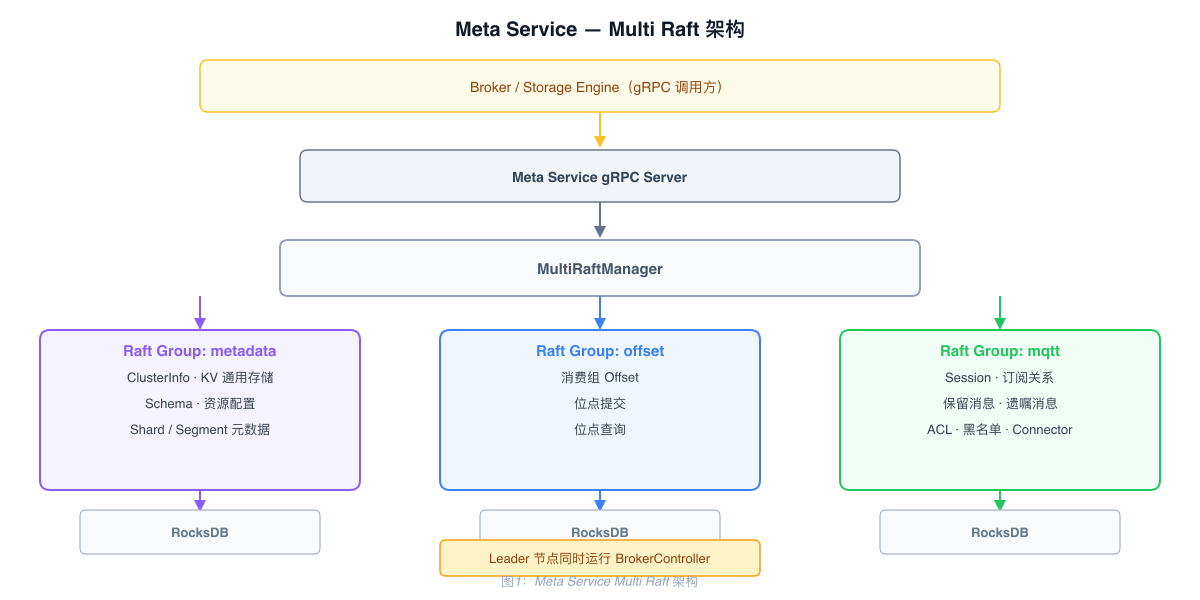
Multi Raft Architecture
Meta Service runs three independent Raft Groups. Each Group has its own Leader and storage, and they operate in parallel without blocking each other:
| Raft Group | Stored Data |
|---|---|
| metadata | Cluster node info, general KV storage, Schema, resource configuration, Storage Engine Shard/Segment metadata |
| offset | Consumer group offset commits and management |
| mqtt | Users, Topics, Sessions, retained messages, will messages, subscriptions, ACL, blocklist, Connectors, shared subscription group Leaders |
Raft Parameters:
| Parameter | Value |
|---|---|
| heartbeat_interval | 250ms |
| election_timeout_min | 299ms |
| write_timeout | 30s (configurable) |
| Slow write warning threshold | 1000ms |
Write Path
Writes that exceed write_timeout (default 30s) return an error. Writes that exceed 1000ms produce a warn log entry.

Data Storage
- Raft logs: Stored in RocksDB, fully recovered after node restart
- Raft snapshots: Generated periodically to compact logs and accelerate node recovery
- Business data: Written to the corresponding RocksDB Column Family via DataRoute
- In-memory cache: CacheManager maintains a hot data cache to reduce RocksDB read pressure; cold data is read and written directly from RocksDB
Controller (BrokerController)
After the Leader node starts, it runs BrokerController, which handles background scheduling:
| Background Task | Description |
|---|---|
| Session expiry cleanup | Periodically scans for expired Sessions and cleans up associated data |
| Last Will delayed delivery | Detects due will messages and triggers delivery to the Broker |
| Storage Engine GC | Cleans up residual data from deleted Shards / Segments |
| Connector scheduling | Creates, assigns, and tracks the status of Connector tasks |
Startup Sequence
- Read
meta_addrsfrom configuration to obtain all Meta Node addresses - Initialize MultiRaftManager, creating the metadata, offset, and mqtt Raft Groups in sequence
- Establish gRPC connections to all nodes, completing cluster initialization and leader election
- Leader node starts BrokerController
- Meta Service is ready and begins serving gRPC requests to Broker and Storage Engine
Comparison with ZooKeeper / etcd
| Dimension | ZooKeeper | etcd | Meta Service |
|---|---|---|---|
| Consensus protocol | ZAB (single Leader) | Single Raft | Multi Raft |
| Storage | All in-memory | BoltDB | RocksDB |
| Scalability | Limited by memory | Limited by single Raft | Each Raft Group scales independently |
| Feature scope | Metadata coordination | Metadata coordination | Metadata + KV storage + Controller |
| External dependency | Yes | Yes | No (built-in) |