Storage Engine Architecture
RobustMQ provides three storage engines. The Storage Adapter shields the upper-layer Broker from the differences between them, and storage type is configured independently per Topic.
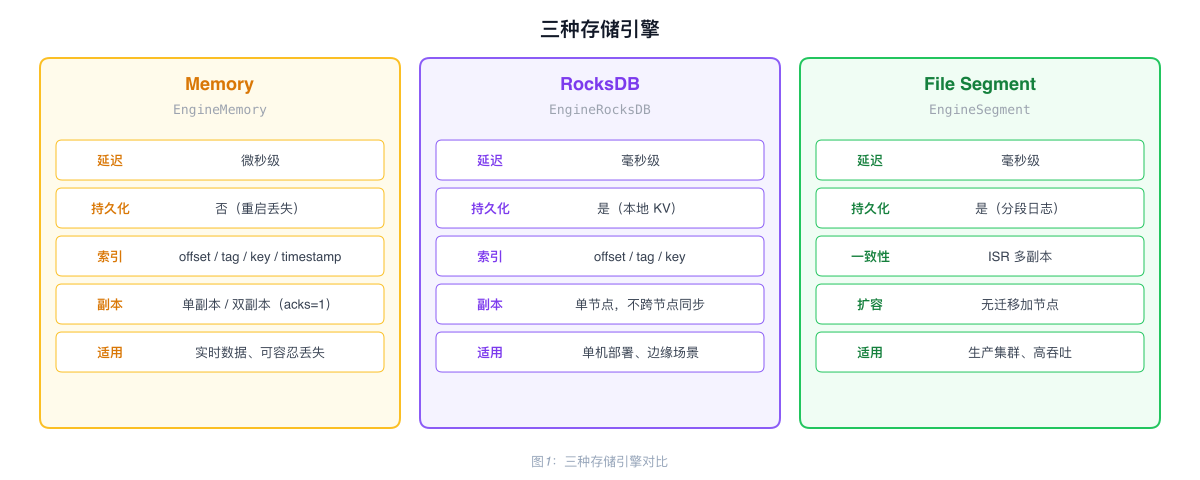
Three Storage Engines
| Engine | Config Value | Latency | Persistent | Use Case |
|---|---|---|---|---|
| Memory | EngineMemory | Microseconds | No | Real-time data, data loss acceptable |
| RocksDB | EngineRocksDB | Milliseconds | Yes | Single-node persistence, edge deployment |
| File Segment | EngineSegment | Milliseconds | Yes | Production clusters, high throughput |
Memory Engine
Pure in-memory storage based on DashMap, supporting four index types:
| Index | Structure | Purpose |
|---|---|---|
| Primary data | DashMap<shard, DashMap<offset, Record>> | Read by Offset |
| Tag index | DashMap<shard, DashMap<tag, Vec<offset>>> | Query by Tag |
| Key index | DashMap<shard, DashMap<key, offset>> | Query by Key (Key is unique) |
| Timestamp index | DashMap<shard, DashMap<timestamp, offset>> | Look up Offset by time |
Data is lost when the process restarts. Supports dual-replica configuration (acks=1): the Leader writes and then asynchronously replicates to the second replica.
RocksDB Engine
Stores messages using a dedicated Column Family (DB_COLUMN_FAMILY_BROKER), with an in-memory write lock per Shard to prevent concurrent write conflicts.
Data is not synchronized between nodes. In cluster mode, different Broker nodes cannot share data, making this engine unsuitable for production clusters.
File Segment Engine
A production-grade storage engine for clustered deployments, supporting multiple replicas, high throughput, and tiered storage.
I/O Pool
A fixed number of I/O Workers (default 16) manage all Partitions. Each Partition maps to a Worker via partition_id % worker_count, so requests for the same Partition always route to the same Worker, preserving write order.
Workers process in batches: block waiting for the first request, then non-blockingly collect subsequent requests. A single batch can aggregate hundreds to thousands of messages, all persisted in one fsync.
Messages use Bytes (Arc reference counting) for zero-copy from network receive to disk write — the data exists in one copy, with references held in different places.
Indexes
RocksDB stores four index types: offset index, time index, key index, and tag index.
Indexes are built synchronously with data writes: when a Worker batch-processes N records, it simultaneously builds all indexes for those N records and writes them via RocksDB WriteBatch in a single operation. One I/O for data files, one I/O for indexes.
The offset index uses a sparse index strategy: one index point per 1000 records, recording the file position for that Offset. On query, the nearest index point is located, then sequential scan covers at most 1000 records. 10 million records require approximately 240KB of index space, with query latency around 2ms.
Consistency Protocol: ISR
Each Active Segment has one Leader, which maintains an ISR (In-Sync Replicas) list. A successful write means data has been replicated to all ISR replicas — no data gaps, reads succeed 100% of the time.
Followers pull data from the Leader in batches (Pull mode). In high-QPS scenarios, this reduces network requests from millions to hundreds.
acks configuration:
| acks | Semantics |
|---|---|
all | Wait for all ISR replicas to confirm |
quorum | Wait for a majority to confirm |
1 | Wait only for Leader to confirm |
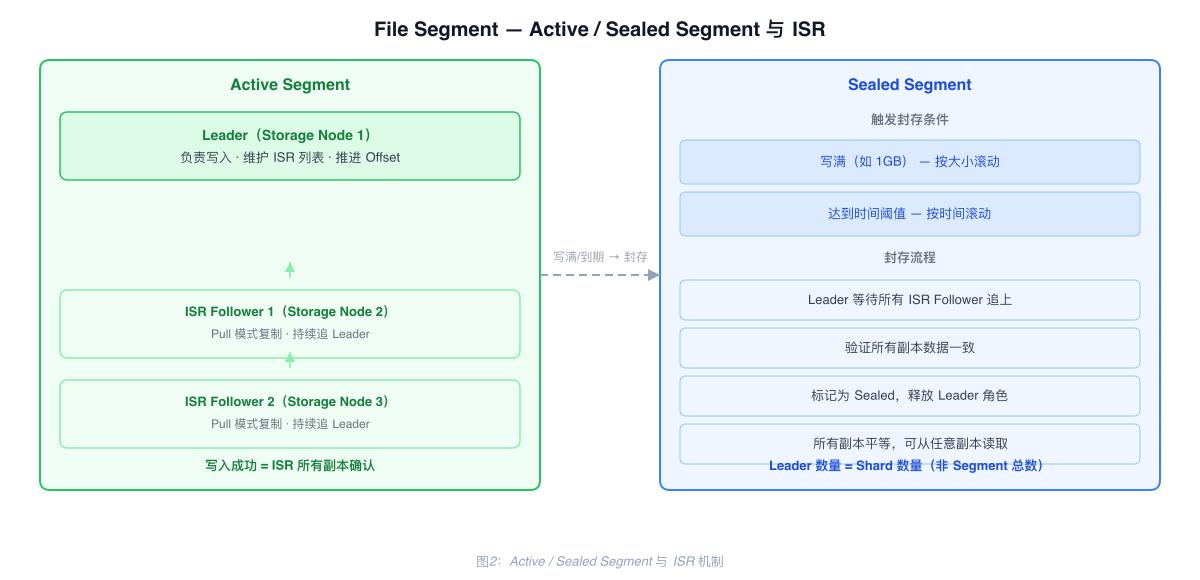
Active Segment and Sealed Segment
Active Segment: The currently-written segment. Has a Leader and ISR mechanism; Followers continuously Pull and replicate.
Sealed Segment: When a Segment fills up (e.g., 1GB) or reaches a time threshold, it is sealed. The Leader waits for all ISR Followers to fully catch up and verifies consistency. Once all replicas are complete and confirmed, the Segment is marked Sealed and the Leader role is released. Sealed Segments have no Leader — all replicas are equal and reads can come from any replica.
Result: Leader count equals Shard count (not total Segment count). 1000 Shards require only 1000 Leaders. Historical data reads are distributed across all Storage Nodes.
Scale-Out
When adding a new Storage Node, no historical data is migrated. Once the current Active Segment fills up, new Segments are automatically assigned to the new node.
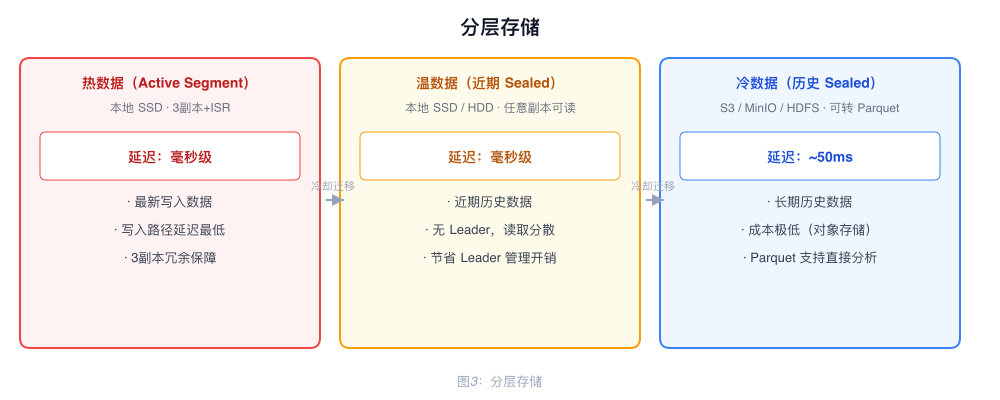
Tiered Storage
Sealed Segments are immutable and can be uploaded directly to S3 from any replica. Updating the metadata completes the migration.
| Data Tier | Storage Location | Latency |
|---|---|---|
| Hot (Active Segment) | Local SSD | Milliseconds |
| Warm (Recent Sealed) | Local SSD/HDD | Milliseconds |
| Cold (Historical Sealed) | S3 / MinIO / HDFS | ~50ms |
Cold data migrated to S3 can be converted to Parquet format, making it directly queryable by analytics tools such as Spark and Hive.
Two File Models
| Model | Description | Use Case |
|---|---|---|
| Partition-per-file | Each Partition has its own file, similar to Kafka | Low latency, high throughput, moderate Topic count |
| Shared-file | Multiple Partitions share a file, similar to RocketMQ | Massive Topics/Partitions |